
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- hadoop
- eks
- apache spark
- 클라우데라
- pyspark
- recommendation system
- 개발자혜성
- redis bloom filter
- 빅데이터
- Python
- Terraform
- 하둡
- kafka
- BigData
- AWS SageMaker
- kubernetes
- 데이터엔지니어
- Spark structured streaming
- DataEngineering
- 개발자
- 블로그
- mlops
- 하둡에코시스템
- Data engineering
- 추천시스템
- cloudera
- spark
- dataengineer
- 빅데이터플랫폼
- 데이터엔지니어링
- Today
- Total
Hyesung Oh
Long running Spark Job Problem: NodeManager is unhealthy 본문
Long running Spark Job Problem: NodeManager is unhealthy
혜성 Hyesung 2022. 4. 27. 19:58EMR Core node의 hdfs (disk)의 점유율이 90% (default threshold 90%) 이상이 되어 해당 node가 unhealthy 상태인 것을 확인할 수 있습니다.
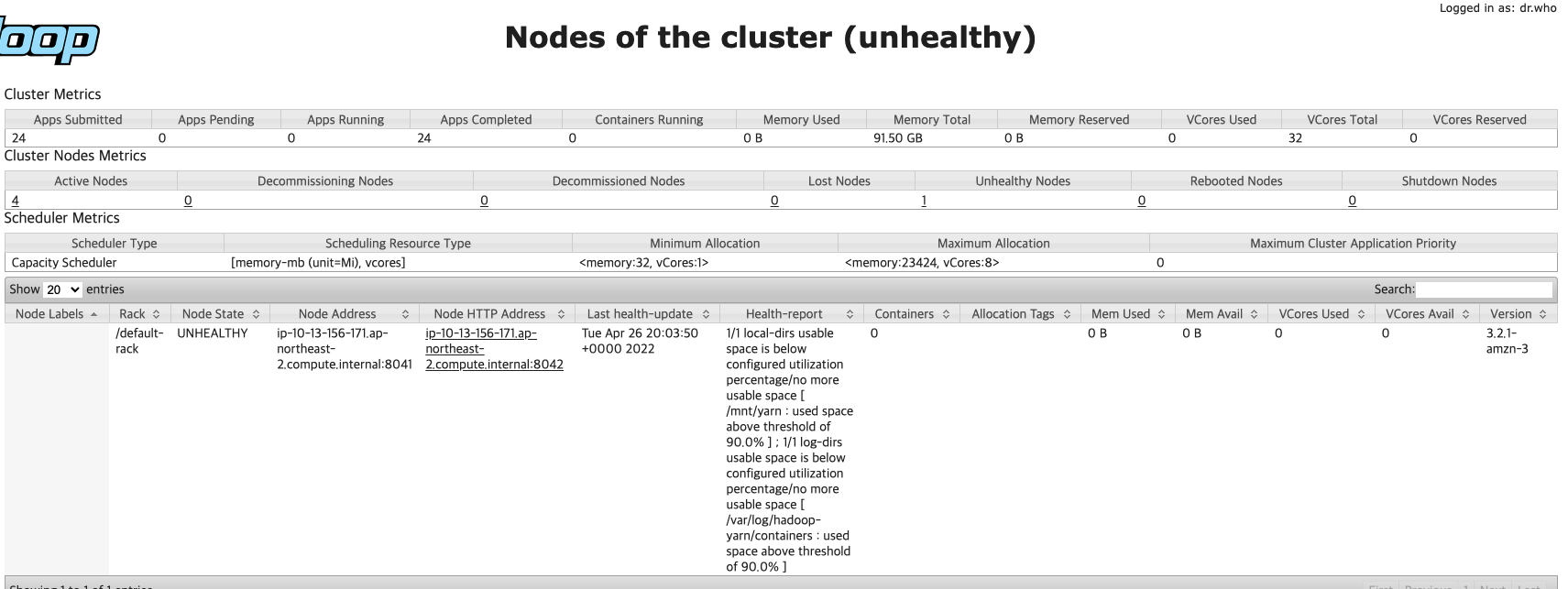
즉, unhealthy를 45분 지속하게 되면 해당 Core node를 termination 처리(정확히는 마킹) 및 NO_SLAVE_LEFT 상태가 되어 job이 실패하게 되는 문제입니다.
AWS Session Manager로 문제가 있는 Core node에 접속하여 hdfs (/mnt/hdfs) 상태를 보니 100% 사용 중임을 확인할 수 있습니다.
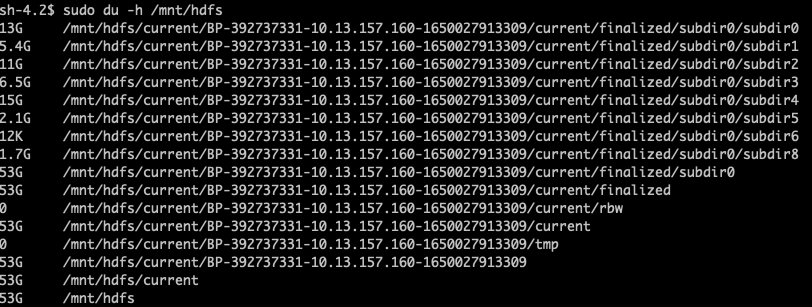

아래는 수동으로 해당 경로의 로그 파일 및 임시 캐시 파일들을 지워준 뒤 모습입니다.

mnt/hdfs/current 지우고 89퍼센트 여유공간 생긴 것을 확인 할 수 있습니다. (cache 파일 삭제 후 4%의 추가 여유 공간 확보되는 것도 확인하였습니다. 총 93%)
다행히 이 문제는 long running spark job의 known issue인 것으로 보입니다.
EMR on EKS에서는 Spark event log rotation 기능을 EMR6.3 부터 지원하기 시작하였습니다.
Rotating Spark event logs can help you avoid potential issues with a large Spark event log file generated for long running or streaming jobs. For example, you start a long running Spark job with an event log enabled with the persistentAppUI parameter. The Spark driver generates an event log file. If the job runs for hours or days and there is a limited disk space on the Kubernetes node, the event log file can consume all available disk space. Turning on the Spark event log rotation feature solves the problem by splitting the log file into multiple files and removing the oldest files.
하지만, EC2 기반 EMR에서는 지원되지 않는 기능이라 곧바로 적용 가능한 솔루션은 아닙니다.
따라서 당분간은 Datadog을 통해 mapred.resourcemanager.NoOfUnhealthyNodes 를 트래킹 하여, 신호 감지 시 (대략 4~5일에 한 번씩) 수동으로 Core Node의 disk를 비워줄 수 있을 것 같습니다.
해당 기능 자동화를 위해 Airflow, hadoop의 webhdfs rest api를 사용해볼 계획입니다.
- Apache Hadoop webhdfs REST API
Apache Hadoop 3.3.3 – WebHDFS REST API
<!--- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or a
hadoop.apache.org
08-WebHDFS REST API 사용법
HDFS는 REST API를 이용하여 파일을 조회하고, 생성, 수정, 삭제하는 기능을 제공합니다. 이 기능을 이용하여 원격지에서 HDFS의 내용에 접근하는 것이 가능합니다. ...
wikidocs.net
-- 정정 2022.06.08--
spark.eventLog.rolling.enabled 옵션은 하나의 큰 event log file을 분절하고 spark.history.fs.eventLog.rolling.maxFilesToRetain 옵션을 함께 활용함으로써 오래된 로그 파일을 없앨 수 있는 기능으로 이해가 되며, Spark.3.0 부터 도입이 되어 활용이 가능 할 것 같습니다. (EMR 버전의 Spark에서 제거하지 않았다면).
please also note that this is a new feature introduced in Spark 3.0, and may not be completely stable
현재도 spark.history.fs.cleaner 옵션을 통해 히스토리 로그를 주기적으로 삭제가 가능할 것으로 보입니다. 다만, 로그파일이 롤링되지 않기 때문에 삭제시 모든 로그가 날아가는 부작용이 있겠으나, 현재도 딱히 확인하고 있지 않은 실정이라 스파크잡의 주기적인 실패 보단 나을 것 같습니다.
spark-default.conf 적용한 옵션입니다.
"spark.history.fs.cleaner.enabled": "true",
"spark.history.fs.cleaner.interval": "6h",
"spark.history.fs.cleaner.maxAge": "6h",'Data Engineering > Apache Spark' 카테고리의 다른 글
| Spark Structured Streaming API의 Kafka Integration 옵션에 대한 이해 (0) | 2022.05.31 |
|---|---|
| AWS EMR: EMRFS의 핵심 기능 들 feat. consistent view, S3-optimized committer (0) | 2022.04.28 |
| Pyspark 도입 후 고도화하기/ 4. Optimization feat. spark-default.conf (0) | 2021.11.02 |
| Pyspark 도입 후 고도화하기/ 3. 가독성 높이기 feat. transform spark3.0 (0) | 2021.11.01 |
| Pyspark 도입 후 고도화하기/ 2. Pyspark 작동 원리 feat. Py4J (2) | 2021.11.01 |