
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 클라우데라
- apache spark
- 개발자
- spark
- 하둡
- eks
- Spark structured streaming
- hadoop
- Python
- 개발자혜성
- 데이터엔지니어
- pyspark
- 블로그
- DataEngineering
- recommendation system
- 하둡에코시스템
- mlops
- kubernetes
- Data engineering
- cloudera
- AWS SageMaker
- redis bloom filter
- kafka
- BigData
- Terraform
- 데이터엔지니어링
- dataengineer
- 빅데이터플랫폼
- 빅데이터
- 추천시스템
Archives
- Today
- Total
Hyesung Oh
빅데이터 플랫폼 Pilot 프로젝트 02 feat. Cloudera Data Platform 본문
반응형
1. Cloudera Data Platform (CDP)
- 세계 최초의 엔터프라이즈 데이터 클라우드.
- CDP를 사용하면 엔터프라이즈급 보안 및 거버넌스를 통해 엣지에서 AI까지 모든 분석 워크로드를 쉽게 처리할 수 있다.
2. CDP 제품 종류
- CDP Public Cloud : Public Cloud version of CDP
- CDP Data Center : On-Premise version of CDP
3. CDP Data Center
3.1 Regular Base Cluster
- 3.1.1 Data Engineering
- HDFS, YARN, YARN Queue Manager,
- Ranger,
- Atlas,
- Hive, Hive on Tez
- Spark
- Oozie
- Hue
- Data Analytics Studio
- 3.1.2 Data Mart
- HDFS, Ranger, Atlas, Hive, Hue
- Operation Database
- HDFS, Ranger, Atlas, Hbas
- Custom Services
3.2. Compute Cluster
- ex) Regular Base Cluster + kafka, hive, impala, spark(Compute Cluster)
자세한 설명은 아래
3.3. 지원 parcel 명세서
| Atlas | Apache Atlas provides a set of metadata management and governance services that enable you to find, organize, and manage data assets. This service requires Kerberos. |
| Core Configuration | Core Configuration contains settings used by most services. Required for clusters without HDFS. |
| Cruise Control | Cruise Control simplifies the operation of Kafka clusters automating workload rebalancing and self-healing. |
| Data Analytics Studio | Data Analytics Studio is the one stop shop for Apache Hive warehousing. Query, optimize and administrate your data with this powerful interface. |
| HBase | Apache HBase는 대규모 데이터 세트에 임의의 실시간 읽기/쓰기 액세스를 제공합니다(HDFS와 ZooKeeper 필요). |
| HDFS | Apache HDFS(Hadoop Distributed File System)는 Hadoop 애플리케이션이 사용하는 기본 스토리지 시스템입니다. HDFS는 데이터 블록에 대한 여러 개의 복제본을 생성하고 이를 클러스터 전반에 걸쳐 컴퓨팅 호스트에 배포하여 안정적이고 매우 빠른 계산을 지원합니다. |
| Hive | Hive는 SQL과 유사한 언어인 HiveQL을 제공하는 데이터 웨어하우스 시스템입니다. |
| Hive on Tez | Hive on Tez is a SQL query engine using Apache Tez. |
| Hue | Hue is the leading SQL Workbench for optimized, interactive query design and data exploration. |
| Impala | Impala에서는 HDFS 및 HBase에 저장된 데이터에 대해 실시간 SQL 쿼리 인터페이스를 제공합니다. Impala에는 Hive 서비스가 필요하며 Hue와 Hive Metastore를 공유합니다. |
| Kafka | Apache Kafka is publish-subscribe messaging rethought as a highly scalable distributed commit log. |
| Key-Value Store Indexer | Key-Value Store Indexer는 HBase에 포함된 테이블 안의 데이터의 변경 사항을 수신 대기하고 Solr을 사용하여 인덱싱합니다. |
| Knox | The Apache Knox Gateway is an Application Gateway for interacting with the REST APIs and UIs of Apache Hadoop deployments. This service requires Kerberos. |
| Kudu | Apache Kudu is a data store that enables real-time analytics on fast changing data. |
| Livy | Apache Livy is a REST service for deploying Spark applications. |
| Oozie | Oozie는 클러스터의 데이터 처리 작업을 관리하는 워크플로우 조정 서비스입니다. |
| Ozone | Apache Hadoop Ozone is a scalable, distributed object store for Hadoop. |
| Phoenix | Apache Phoenix is a scale-out relational database that supports OLTP workloads and provides secondary indexes, materialized views, star schema support, and common HBase optimizations. Phoenix uses Apache HBase as the underlying data store. |
| Ranger | Apache Ranger is a framework to enable, monitor and manage comprehensive data security across the Hadoop platform. This service requires Kerberos. |
| Schema Registry | Schema Registry is a shared repository of schemas that allows applications to flexibly interact with each other. A common Schema Registry provides end-to-end data governance and introduces operational efficiency by saving and retrieving reusable schema, defining relationships between schemas and enabling data providers and consumers to evolve at different speeds. |
| Solr | Solr은 HDFS에 저장된 데이터를 인덱싱 및 검색하는 배포 서비스입니다. |
| Spark | Apache Spark is an open source cluster computing system. This service runs Spark as an application on YARN. |
| Streams Messaging Manager | Streams Messaging Manager (SMM) is an operations monitoring and management tool that provides end-to-end visibility in an enterprise Apache Kafka environment. |
| Streams Replication Manager | Streams Replication Manager (SRM) is an enterprise-grade replication solution that enables fault tolerant, scalable, and robust cross-cluster Kafka topic replication. |
| Tez | Apache Tez is the next generation Hadoop Query Processing framework written on top of YARN. |
| YARN (MR2 Included) | YARN이라고도 하는 MRv2(Apache Hadoop MapReduce 2.0)는 MapReduce 애플리케이션을 지원하는 데이터 계산 프레임워크입니다(HDFS 필요). |
| YARN Queue Manager | YARN Queue Manager is the queue management user interface for Apache Hadoop YARN Capacity Scheduler. |
| Zeppelin | Apache Zeppelin is a web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more. |
| ZooKeeper | Apache ZooKeeper는 구성 데이터를 유지하고 동기화하는 중앙 집중식 서비스입니다. |
3.4. CDH & HDP와의 차이점
- CDH와 HDP에서 지원해주던 모든 기능을 사용할 수 있습니다.
이해하기 쉽게 밴다이어그램으로 표현해보았습니다.
- CDP 자체에서 추가적으로 지원하는 기능이 있습니다.
여기서 VPC의 경우는 CDH5.0부터 지원하는 아키텍처 였으나, CDH6.3부터 개선점이 많아졌다고 합니다.
HDFS Erasure Coding의 경우 Canyon Cluster HDFS에 현재 도입을 하고 있는 것으로 이해하고있습니다.
4. Virtual Private Cluster
4.1. Regular Cluster와 Compute Cluster로 구성.
4.2. Architecture
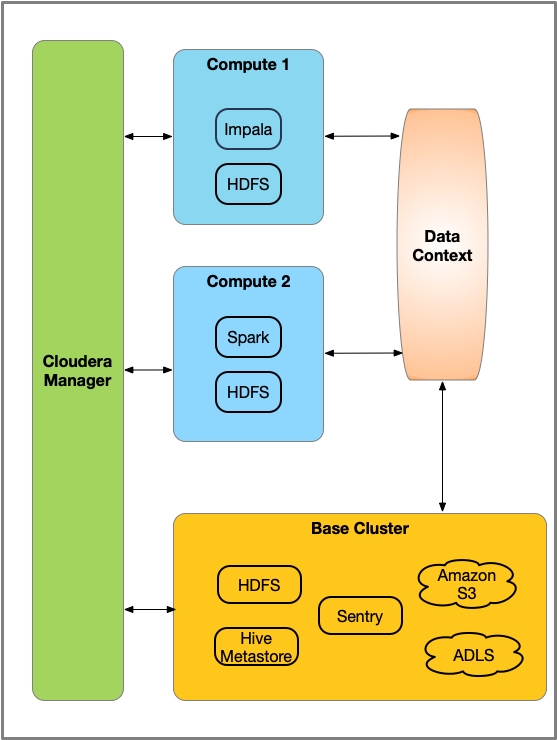
4.3. Trade off
- 장점 : workload isolation을 통한 resource 경합 완화, 배포 용이, 클러스터 유지 보수성 측면 향상
- 단점 : base cluster - data context와의 network을 통한 data 송수신을 해야하기 때문에 일정 수준이상의 트래픽을 요구될 시 부적합한 아키텍처.
- 자세한 사항은 여기를 참고
4.4. CDH 지원
- CDH 5부터 지원
- CDH 6.3부터 VPC Improvement 요소가 있다고함.
- impala executer의 local storage를 이용한 cache backed data를 이용하여 scan-heavy query 시에 high latency 완화
- 이 밖에 Hive, Hue 개선
- 요약 하면, VPC의 Compute Cluster, Base Cluster간 네트워크 데이터 송수신 한계점을 보완해나가고 있다는 것
4.5. Compute Cluster 설정 방법
- 최초 Regular Cluster(Base Cluster)를 생성한 후 아래같이 Regular Cluster(초기 생성 클러스터)와 동일한 과정을 통해 추가할 수 있음
반응형
'Data Engineering' 카테고리의 다른 글
| 빅데이터 플랫폼 Pilot 프로젝트 04 feat. Cloudera Data Platform (0) | 2020.08.31 |
|---|---|
| 빅데이터 플랫폼 Pilot 프로젝트 03 feat. Cloudera Data Platform (0) | 2020.08.31 |
| 빅데이터 플랫폼 Pilot 프로젝트 01 feat. Cloudera Data Platform (0) | 2020.08.31 |
| Apache Ozone (1) | 2020.08.22 |
| [데이터 처리 기술의 이해] 데이터 처리 프로세스 #5 대용량의 비정형 데이터 처리방법 (0) | 2020.05.20 |
'Data Engineering' Related Articles
more



Comments