
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 하둡에코시스템
- DataEngineering
- 블로그
- Spark structured streaming
- AWS SageMaker
- hadoop
- mlops
- 데이터엔지니어
- eks
- kubernetes
- BigData
- kafka
- 빅데이터
- Python
- 빅데이터플랫폼
- Data engineering
- Terraform
- cloudera
- recommendation system
- redis bloom filter
- 개발자혜성
- dataengineer
- 개발자
- 데이터엔지니어링
- 클라우데라
- apache spark
- 하둡
- spark
- 추천시스템
- pyspark
- Today
- Total
Hyesung Oh
#python#crawling#networkx - 연관검색어 크롤링 및 시각화 [1] 본문
오늘은 제가 인턴 입사 과제로 이틀동안 풀었던 문제를 소개할까 합니다.
문제는 아래와 같습니다.

- 기본적인 크롤링 단계

requests : 서버에 요청하여 응답을 받아옴
bs4: 응답을 통해 받아온 페이지에서 우리가 원하는 부분을 파싱할 수 있도록 해주는 모듈

r : 서버 응답. 서버가 정상 응답을 하였다면 print(r) 결과로 200을 출력해야함.
bs4_r : 응답에 BeautifulSoup 을 먹여줌으로서 페이지에
서 원하는 부분을 태그파싱을 통해 가져올 수 있게 해줌.
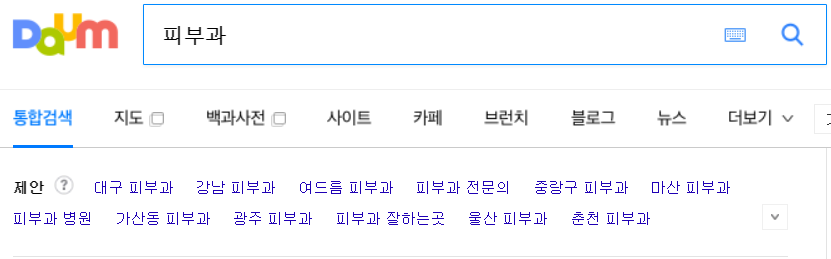

tag: div class: llist_keyword_type2 하위에 있는 tag: span, class: wsn 을 따와서 span_list 에 리스트형태로 저장한다. span_list 의 각 요소에는 연관 검색어 정보가 포함되어있다.
해당 페이지에서 f12 개발저 도구 버튼을 누르면 아래와 같이

*tip - 우리가 원하는 연관검색어가 있는 부분에 대한 태그를 찾을 수 있다. 좌측 상단의 화살표 버튼을 눌러서 페이지의 원하는 부분을 클릭하면 해당 부분의 태그를 위 사진과 같이 검은색으로 표시해준다.

연관 검색어가 포함되어 있는 span_list의 요소에서 span_list[i].text 를 해줌으로서 우리가 원하는 검색어 단어 부분만 가져올 수 있다.

이제 위 단계를 함수로 만들어 함수안에서 함수를 호출하는 재귀함수를 만들어 봄.


위 함수를 시행하면 아래와 같습니다.
각 크롤링 단계의 결과는 데이터 프레임형태로 전역 변수 딕셔너리에 저장하도록 했습니다.

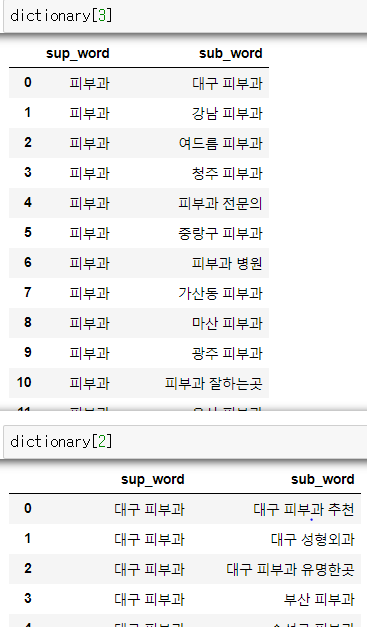
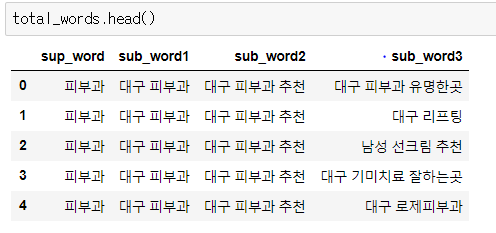
다음 포스팅에서는 크롤링한 검색어와 연관검색어간의 관계를 networkx 를 이용하여 간단히 시각화 해본 것을 공유하도록 하겠습니다.
'DEV > Python' 카테고리의 다른 글
| Python, Node.js로 끄적여본 async, await (0) | 2022.08.11 |
|---|---|
| Regular Expression, Regex 정규표현식 문자 (0) | 2020.01.29 |
| #python#crawling - get, post 차이 이해 및 post 방식 동적 크롤링 실습 [2] (1) | 2019.08.22 |
| #python#crawling - get, post 차이 이해 및 post 방식 동적 크롤링 실습 [1] (0) | 2019.08.22 |
| #python#crawling#networkx - 연관검색어 크롤링 및 시각화 [2] (0) | 2019.08.22 |


