
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- recommendation system
- 추천시스템
- Data engineering
- AWS SageMaker
- pyspark
- spark
- 개발자혜성
- Spark structured streaming
- 개발자
- redis bloom filter
- mlops
- BigData
- dataengineer
- 하둡에코시스템
- apache spark
- hadoop
- 데이터엔지니어링
- 데이터엔지니어
- cloudera
- kafka
- 클라우데라
- Terraform
- Python
- 빅데이터
- 블로그
- eks
- kubernetes
- 빅데이터플랫폼
- DataEngineering
- 하둡
- Today
- Total
Hyesung Oh
#python#crawling - get, post 차이 이해 및 post 방식 동적 크롤링 실습 [2] 본문
금융투자협회 채권정보센터 KOFIABOND 에서 20년치 채권 만기수익률 데이터를 크롤링을 해보겠습니다.
URL: http://www.kofiabond.or.kr/index.html
홈화면 -> 우측상단 시가평가-> 채권 시가평가기준 수익

채권종류, 만기일 선택 -> 조회하기 버튼
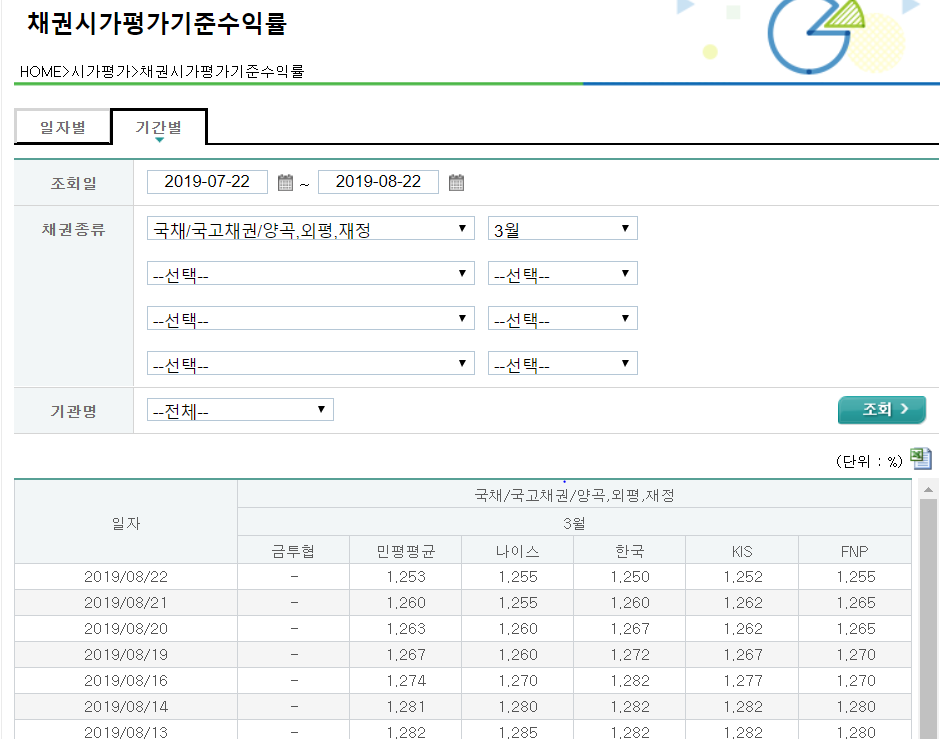
다음과 같은 채권 만기수익률 시계열 데이터를 조회할 수 있습니다.
위는 예시로서 2019.7.22 - 2019.8.22 한달 간의 데이터를 조회한 것입니다.
만약 20년 동안의, 모든 채권, 만기일에 대한 데이터를 받아오고 싶을 때는 어떻게 해야할까요?
- 하나하나 설정하고 조회하기 버튼을 누르고 다운받는다 (수작업)
- requests.get(target url) (GET 방식)
1번을 선택하신다면 건투를 빌겠습니다.
2번은 잘못된 적절하지 못한 방법일 뿐더러 원하는 정보를 요청할 수 없습니다.
이유는 간단합니다. 조회하기 전과 후의 해당 페이지의 URL은 변함 없이 동일하기 때문입니다.


이러한 경우를 동적인 웹페이지라 표현합니다. 쉽게 말하면 client 에게 보여지는 URL 외에 보이지 않는 무언가가 있다는 뜻입니다.
selenium 을 이용한 방식을 선택하실 수 도 있지만 이는 로컬 환경에 따라 여러 제약과 변수가 발생할 수 있습니다.
따라서 이번 포스팅에서는 REST API의 POST 크롤링 방법에 대해 알아보겠습니다.
우리가 해야할 작업은 크게 두가지입니다.
- URL 확보
- header 로 넘겨줄 string format 확보
순서대로 따라 해보시기 바랍니다.
F12 버튼 -> Network -> 해당 페이지로 돌아가서 채권 종류, 만기일 선택 -> 조회하기 -> Network 창 확인

위에서 볼 수 있듯이 POST 방식을 사용하여 서버에 정보를 요청했음을 알 수 있습니다.
1. URL : http://www.kofiabond.or.kr/proframeWeb/XMLSERVICES/
위와 동일한 상태에서 스크롤 내림 -> form data

(인덴테이션 생략)
2. form_data =
<message> <proframeHeader> <pfmAppName>BIS-KOFIABOND</pfmAppName> <pfmSvcName>BISBndSrtPrcSrchSO</pfmSvcName> <pfmFnName>selectTrm</pfmFnName> </proframeHeader> <systemHeader></systemHeader> <BISBndSrtPrcTrmDTO> <val31>1010000</val31> <val32>0003</val32> <standardDt1>20190722(조회시작일)</standardDt1> <standardDt2>20190822(조회종료일)</standardDt2> </BISBndSrtPrcTrmDTO> </message>
일반화 하면 다음과 같습니다.

* 저의 경우 모든 채권종류, 만기에 대해 수집하는 것을 보여드리기 위해 조회 가능한 모채권 종류, 만기일을
먼저 수집하여 데이터 프레임에 저장하도록 하겠습니다.
- 채권종류 수집

<pfmFnName> 태그 내용이 selectBndType 으로 바뀐 것을 눈치 채셔야 합니다. 채권 종류 요청시 서버에 넘겨주어야 하는 form_data 입니다.
메커니즘은 다음과 같습니다.
- 기본 url + form_data 를 함께 requests.post()에 넘겨줍니다. r = requests.post(url,form_data)
- 받아온 응답에 beautifulsoup을 먹인후 원하는 데이터가 있는 tag 를 찾아서 파싱하여 데이터 프레임에 저장합니다.


- 채권 만기일 수집


* 과정은 동일하며 또한 최종 만기수익률 데이터 크롤링시에도 같은 과정이 적용됩니다.
[3]편에 이어서..
'DEV > Python' 카테고리의 다른 글
| Python, Node.js로 끄적여본 async, await (0) | 2022.08.11 |
|---|---|
| Regular Expression, Regex 정규표현식 문자 (0) | 2020.01.29 |
| #python#crawling - get, post 차이 이해 및 post 방식 동적 크롤링 실습 [1] (0) | 2019.08.22 |
| #python#crawling#networkx - 연관검색어 크롤링 및 시각화 [2] (0) | 2019.08.22 |
| #python#crawling#networkx - 연관검색어 크롤링 및 시각화 [1] (1) | 2019.08.21 |

