
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 빅데이터
- 추천시스템
- kubernetes
- kafka
- hadoop
- BigData
- apache spark
- DataEngineering
- dataengineer
- Spark structured streaming
- AWS SageMaker
- Data engineering
- 개발자
- 개발자혜성
- Terraform
- spark
- 데이터엔지니어
- redis bloom filter
- mlops
- Python
- 하둡에코시스템
- 데이터엔지니어링
- 클라우데라
- eks
- 하둡
- pyspark
- 빅데이터플랫폼
- 블로그
- cloudera
- recommendation system
- Today
- Total
Hyesung Oh
#python#crawling#networkx - 연관검색어 크롤링 및 시각화 [2] 본문
이어서 networkx 모듈을 사용한 시각화 방법에 대해 포스팅 하겠습니다.
*저는 이번 과제를 하면서 networkx 모듈을 처음 공부하며 사용해보았습니다. 때문에 사용 방법에 있어서 미숙한 부분이 있을 수 있습니다.
모듈 소개에 앞서 우선 네트워크란 무엇인지 간단하게 알고 넘어가겠습니다.
-
네트워크의 구조
| 그래프 | 버텍스 | 링크 |
| 네트워크 | 노드 | 엣지 |
상-하 단어는 같은 의미로서 물리학, 수학에서 각기 다르게 사용되는 용어일 뿐입니다. 필자는 네트워크, 노드, 엣지라 칭하겠습니다.
-
네트워크 구조 표현 방법 3가지
| 인접 행렬 |
| 네트워크 |
| 테이블 |
인접 행렬 (adjcent matrix) :
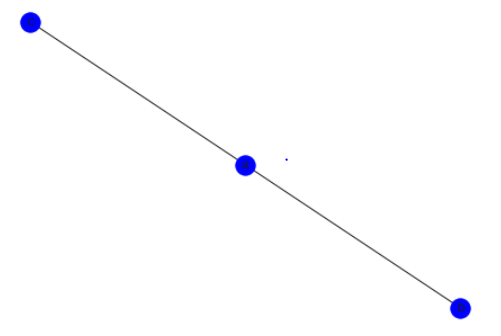
위와 같은 네트워크가 있다고 가정할 때, 이 네트워크의 인접행렬 표현은 아래와 같습니다.
| a | b | c | |
| a | 0 | 1 | 1 |
| b | 1 | 0 | 0 |
| c | 1 | 0 | 0 |
*각 셀은 노드간의 연결 횟수입니다. 위는 방향성을 가지지 않는 네트워크지만, 방향성을 가지는 네트워크 또한 인접행렬로 표현이 가능합니다. ex) ab 1 ba 0 이런식으로..
-
왜 네트워크 분석을 사용하는가?
이유는 바로 환원주의 오류에서 벗어나기 위함입니다. 환원주의라면 숲 보다는 나무를 보는 것에 비유를 할 수 있습니다. 각 개체에만 집중하는 것이 아니라 각 개체간의 유기적인 연결관계를 분석함으로서 시스템을 좀더 효율적으로 최적화 할 수 있는 방법을 모색할 수 있는 기대효과가 있습니다.
-
네트워크 분석기법에는 어떤 것들이?
- 노드 중요도 측정
- degree centrality: 각 노드의 연결 수 고려
- between centrality: 전체적인 연결 흐름 고려. (연결 수는 적지만 중요한 노드)
- closeness centrality: 어떤 노드에서든 가깝게 접근할 수 있는 노드
- eigenvector centrality: 접근성 뿐만 아니라 노듣별 가중치를 고려
2. 네트워크 구조 측정
- radius (반지름) 기준
- clustering coefficient
- degree assortativity (일종의 상관계수)
3. 커뮤니티 탐지
: 분석 노드 갯수가 많고 복잡할 때 커뮤니티 탐지법을 이용해 커뮤니티 단위로 분석하여 커뮤니티별 차이점과 새로운 정보를 도출할 수 있음.
* 네트워크 분석법에 대해서는 추후 자세히 다루도록 하겠습니다
이제 본론으로 넘어가서 networkx 모듈에 대해 소개하겠습니다.
-
networkx 설치법
우선 https://networkx.github.io/documentation/latest/install.html <-- networkx document 를 보시고 released version 설치를 하시면 됩니다.
* jupyter notebook 상에서 설치시: !pip install networkx 실행
-
tutorial
다음으로 가장 기본적인 networkx tutorial 입니다.
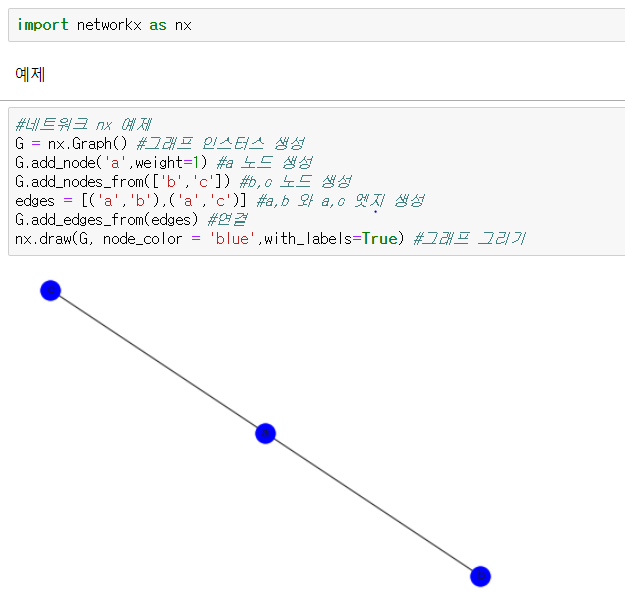
-
tutorial 을 응요하여 이전 [1] 포스팅에서 크롤링한 데이터 시각화

우선 노드에 각 단어를 입력하기 위해선 한글 폰트 설정이 필요합니다.

하지만 released version 에서는 set_fontproperties 메소드가 지원되지 않는 것 같습니다. 이를 해결하기 위해선
https://networkx.github.io/documentation/latest/install.html
Install — NetworkX 2.4rc1.dev20190815182716 documentation
NetworkX requires Python 3.5, 3.6, or 3.7. If you do not already have a Python environment configured on your computer, please see the instructions for installing the full scientific Python stack. Note If you are on Windows and want to install optional pac
networkx.github.io
https://scipy.org/install.html
Installation — SciPy.org
Installation Installations methods include: Methods differ in ease of use, coverage, maintenance of old versions, system-wide versus local environment use, and control. With pip or Anaconda’s conda, you can control the package versions for a specific proje
scipy.org
를 참고하시길 바랍니다.
하지만 저는 window10 에서 특정 모듈 설치시 오류가 발생하는 문제를 해결하지 못하였고 차선책으로 각 단어를 숫자에 mapping 하여 시각화 하였습니다.

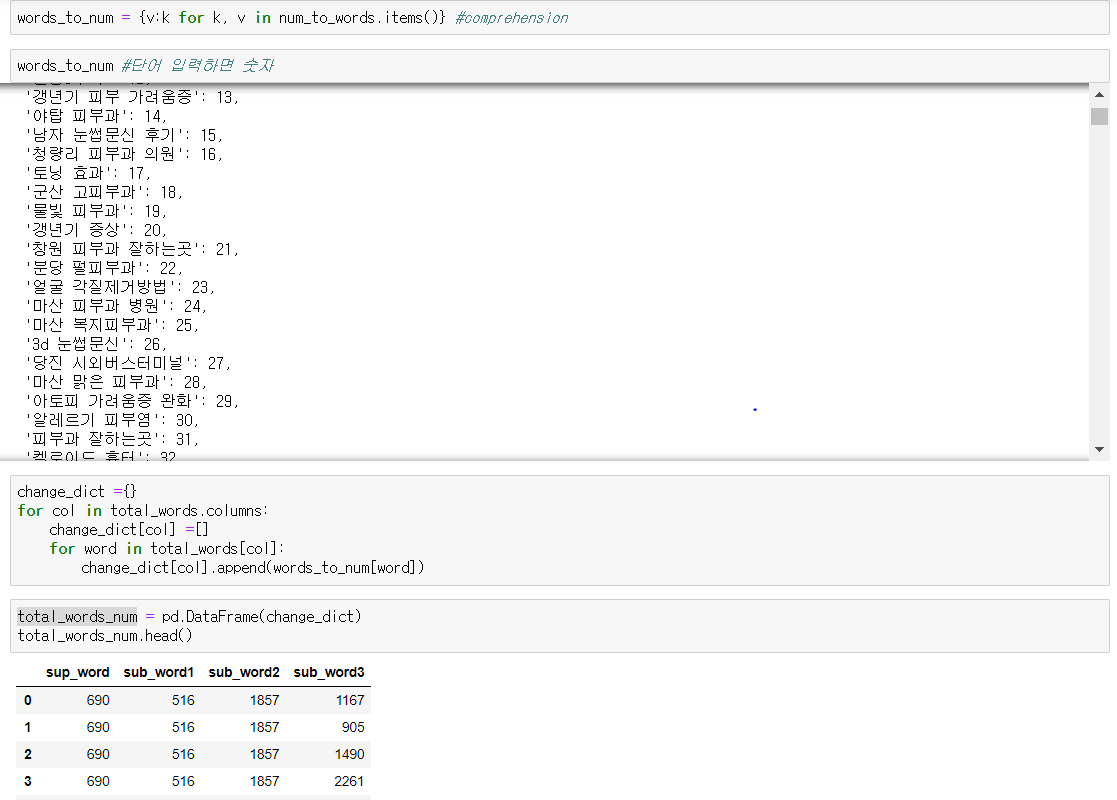
최종적으로 단어를 숫자로 대체한 total_words_num 이라는 데이터 프레임을 사용하였습니다.
다음은 그래프 그리는 함수 코드입니다.

* 위의 포문은 사용한 단어 데이터프레임 컬럼이 4개라 네번 반복되는 모양새 입니다. 하지만 이 부분은 크롤링 횟수에 따라서 계속 변경해주어야 하는 문제가 발생합니다. 따라서 데이터 프레임 컬럼의 길이에 따라 반복문 횟수를 조절해서 시행해주는 코드로 바꿔주시면 좀더 효율적인 코드가 될 것 같습니다.

G.degree 는 각 노드의 연결 횟수를 반환합니다. 하지만 최신버전부터 dictionary 형태로 반환되지 않기 때문에 dict(G.degree) 로 저장을 해서 nodelist = d.keys() 에 넘겨주도록 합니다. 이를 통해 각 노드의 연결횟수에 따라 노드의 크기를 자동으로 지정할 수 있습니다.
아래는 결과물입니다.
* 400개만 시각화 (4천개는 너무 많아 10분의 1로 줄여서 시각화 하였습니다)
- red: sup_word
- blue: sub_word1
- green: sub_word2, sub_word3


'DEV > Python' 카테고리의 다른 글
| Python, Node.js로 끄적여본 async, await (0) | 2022.08.11 |
|---|---|
| Regular Expression, Regex 정규표현식 문자 (0) | 2020.01.29 |
| #python#crawling - get, post 차이 이해 및 post 방식 동적 크롤링 실습 [2] (1) | 2019.08.22 |
| #python#crawling - get, post 차이 이해 및 post 방식 동적 크롤링 실습 [1] (0) | 2019.08.22 |
| #python#crawling#networkx - 연관검색어 크롤링 및 시각화 [1] (1) | 2019.08.21 |


